


Algorithm
As I look around a room and identify objects, there are three different things that I am using.
Application
I wrote an application to test whether it would be possible to easily train an application to recognize objects and then test how well it worked. The application was written in C# and the source is available.
Training
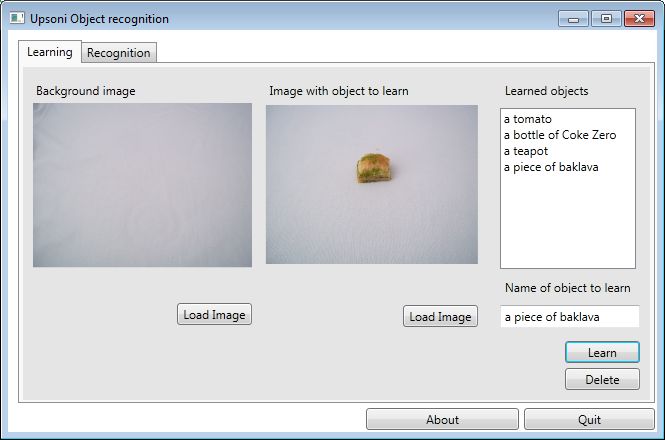
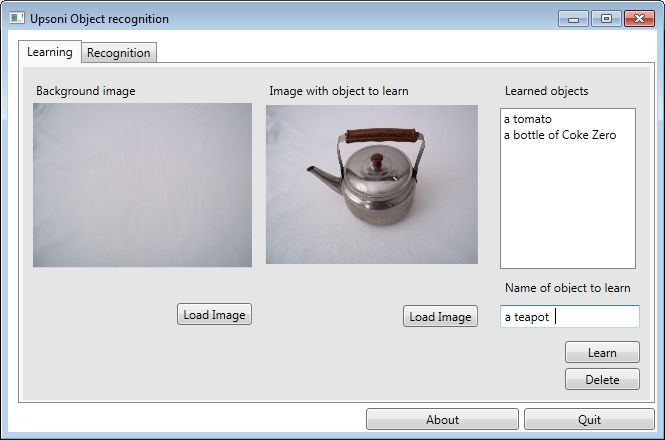
The learning UI is simple to use, you load an image of a background and then the same background with the
image to learn added. What the application does is analyze the palette of the background and learning images
and the difference is the palette of the object to learn. It then serializes that palette out to an XML file,
along with the image name.
Recognition
The palette of the image to be analyzed is loaded and then the palette of each image signature learned during training is compared. Any signature which has a palette that is mostly or wholly represented in the photo is deemed a match. This works well with objects that have an unusual color palette, but poorly with objects that have a palette that match other common objects. Bananas, for example, work quite well, but anything that is primarily black or primarily white will tend to match many common objects.
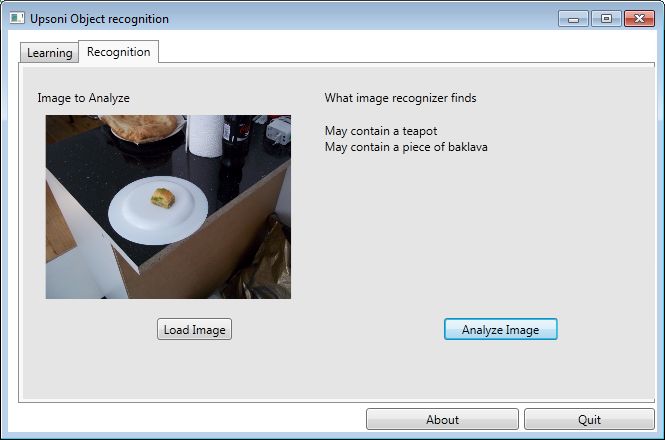
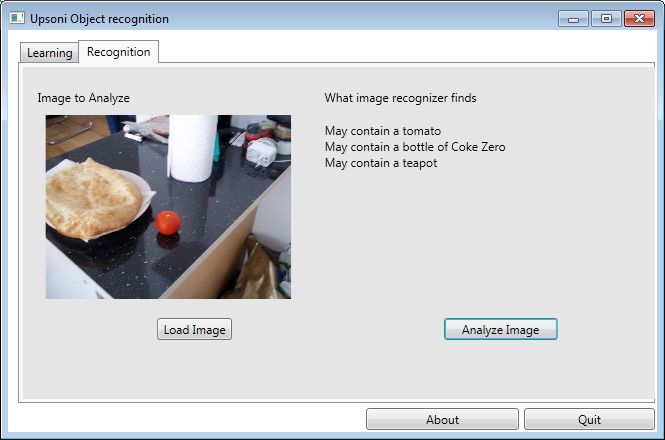
These screen captures show the object recognition correctly returning an identification of what is in the images,
but also having false positives. False negative were rare if the light level was similar to the learning light
level, but false positives were common for certain objects (particularly black or white objects).
Problems with the simplistic approach
I'm somewhat surprised this works at all, but it actually works reasonably well. Some things in particular, for example a blue sky, are very well identified using this method. If the image were decomposed into blobs, and the color signature, not just the palette but the amount of each color, were analyzed against the blob it would give much more accurate results. Additionally, the visual texture and morphology of the blobs would give better results, but would be much harder to learn and to analyze. Another issue is light level, but that can addressed with modifying the color palette based on light level of the learning image vs light level of the image to analyze.
Code
The object recognition source code is available under a creative commons CC BY license. I intend to upload it to GitHub at some point in the near future, but for now it is just a zip file.
 Computer vision
Computer vision
Artificial intelligence
Effecting the physical world
Our robot controller app is available in the app store and will be be available soon for Android
